
心理所合作研究揭示抑郁癥污名信息在社交媒體環境下的心理語言表達模式
抑郁癥是一種嚴重的心理疾病,根據世界衛生組織(WHO)的數據顯示,2015年,全球約有4.4%的人口受到抑郁癥的困擾。接受專業的心理健康援助是降低抑郁癥危害的有效措施。但是,現實社會中存在著抑郁癥污名現象,這一現象會在抑郁癥患者身上加諸恥辱性標簽,引發他人對患者的歧視、排斥,從而導致抑郁癥患者因羞于主動尋求心理健康援助而錯失最佳心理干預時期。減少抑郁癥污名現象將有利于改善抑郁癥患者的心理健康水平。
大眾媒體(電視、報紙、廣播等)是信息傳播的重要渠道。理解抑郁癥污名信息的特征,有利于從海量的大眾媒體信息中識別、研究抑郁癥污名信息,從而為制定相應的干預策略提供有益的幫助。近年來,伴隨著互聯網的發展,社交媒體(如Twitter、新浪微博)已經逐漸成為一種新型的大眾媒體。與傳統的大眾媒體相比較,新媒體環境下的信息內容與溝通方式均發生了巨大的變化。但是,新媒體環境下的抑郁癥污名信息的特征至今尚不明確。
基于上述背景,中國科學院行為科學重點實驗室朱廷劭研究組聯合北京林業大學李昂組開展研究,旨在探索抑郁癥污名信息在社交媒體環境下的心理語言表達模式。
該研究以新浪微博為研究平臺,利用應用程序接口(API)下載了超過一百萬名活躍用戶公開發表的微博,并從中篩選出15879條帶有抑郁癥關鍵詞的微博,形成一個子數據集。在此基礎上,一方面,利用人工編碼方法,分析子數據集中每條微博的內容是否反映了抑郁癥污名,以及具體反映了哪種類型的抑郁癥污名,將編碼結果作為因變量;另一方面,利用心理語言分析方法,通過簡體中文版LIWC程序,從每條微博的內容中提取66類心理語言特征,將特征取值作為自變量。隨后,利用機器學習方法(Logistic回歸、神經網絡、支持向量機、隨機森林),分別建立兩種不同用途的分類預測模型:(1)旨在區分污名與非污名微博的分類預測模型、(2)旨在區分不同類型的污名微博的分類預測模型。
研究結果顯示,在15879條微博中,6.09%的微博被確認為抑郁癥污名信息。其中,最常見的三種污名類型是:(1)認為抑郁癥患者的言行舉止難以預料(不可預知污名)、(2)認為罹患抑郁癥是個性軟弱的表現(軟弱污名)、(3)認為抑郁癥不是一種醫學疾病(詐病污名)。分類預測模型的訓練結果顯示(見圖1),區分污名與非污名微博的精確度可以達到75.2%(F-Meaure);區分最常見的三種類型的污名微博的精確度可以達到86.2%(F-Measure)。微博用戶在發布抑郁癥污名信息時,會更多使用一些特定類別的詞匯,包括:差距詞、排除詞、消極情緒詞、社會歷程詞、暫定詞。
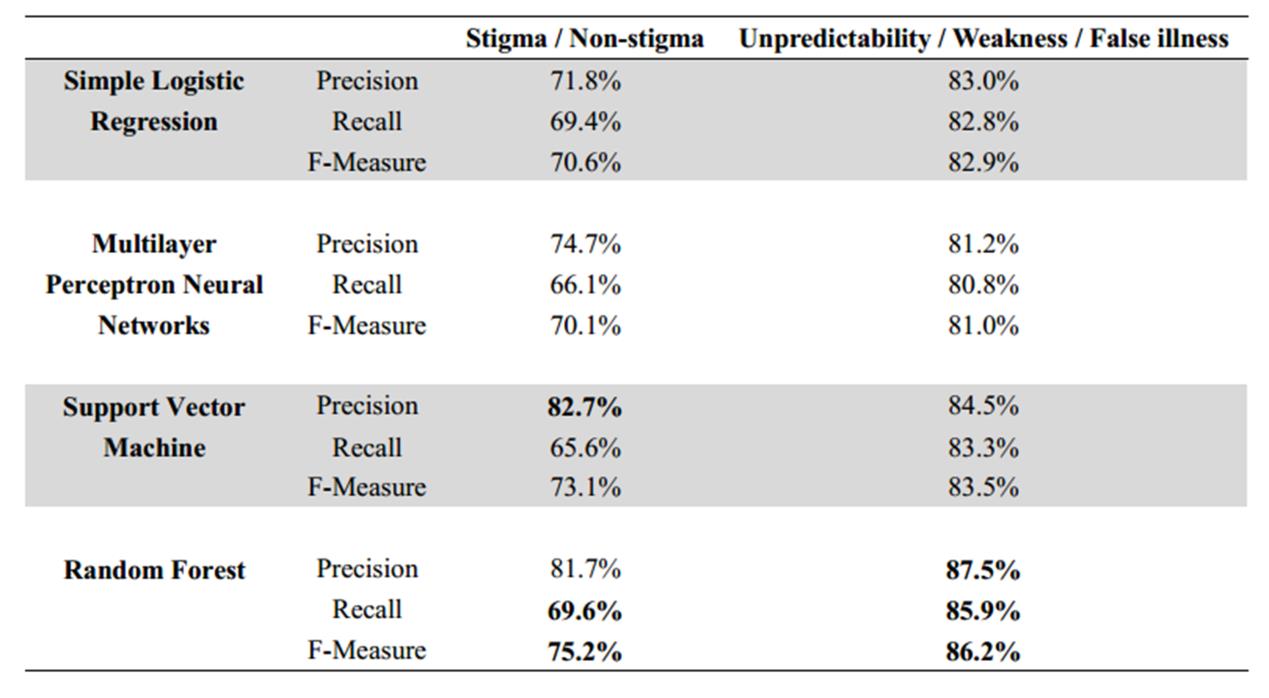
圖1 分類預測模型的訓練結果
該研究發現了抑郁癥污名信息在社交媒體環境下的心理語言表達模式,證明利用心理語言分析方法有助于實現抑郁癥污名信息的在線識別。利用建立好的分類預測模型,可以在社交媒體環境下對海量用戶信息開展實時、自動監測,提高對抑郁癥污名信息的識別效率。
該研究受國家重點基礎研究發展計劃(2014CB744600)的課題資助。相關研究成果在線發表于國際學術期刊Journal of Affective Disorders:
Li, Ang., Jiao, Dongdong., Zhu, Tingshao. (2018). Detecting depression stigma on social media: A linguistic analysis. Journal of Affective Disorders. DOI: https://doi.org/10.1016/j.jad.2018.02.087
附件下載: