
心理所與自動化所合作建立大規模詞匯語義維度評分數據庫
如何對語義信息進行量化表示一直是認知科學的一大難題。近年來,人工智能領域出現的分布式語義模型在這方面取得了重大的成功。但是,這一類語義模型的底層維度的心理現實性較低,阻礙了其在心理、教育、認知神經科學等領域的一些應用。另一方面,心理學和認知神經科學揭示出了大腦中支持語義表征的主要系統,提出了與這些系統相對應的經驗語義維度,進而開發出了相應的主觀評分方法來對其進行量化。這一類語義維度具有較高的心理和神經現實性。有研究發現,基于此類主觀語義評分所構建的語義模型相比常用的分布式語義模型能夠更好地擬合和解釋大腦中的神經活動。
目前,圍繞上述兩類量化語義維度的研究都在如火如荼地展開,但各自都難以對大量自然語言進行可解釋化的量化語義分析:分布式語義模型雖然能夠量化表示所有詞的語義信息,但其語義維度的心理現實性不足;經驗語義維度的可解釋性高,但評分成本也高,難以覆蓋所有詞,不能滿足對任意自然文本進行分析的需求。為了解決上述問題,中國科學院行為科學重點實驗室李興珊課題組的林楠副研究員與中科院自動化所王少楠副研究員組織各自所在研究團隊成員開展跨學科合作,結合心理學和人工智能兩大學科的優勢,構建了大規模詞匯語義維度評分數據庫——六維語義數據庫。
研究者首先圍繞心理學和認知神經科學所揭示出的六個主要語義維度,即視覺、動作、社會、情感、時間、空間,針對17940個常用中文詞,開展了大規模的主觀語義評分實驗。進而,研究者結合評分實驗的結果和分布式語義模型,對約143萬中文詞和152萬英文詞的六維語義評分進行了估算。最后,研究者結合本實驗的數據以及其他已發表的多個中、英文語義評分數據庫,對所獲得的主觀語義評分和估算語義評分進行了多項信度和效度檢驗。結果顯示六維語義數據庫所包含的主觀評分和計算估計評分都具備較高的信效度。
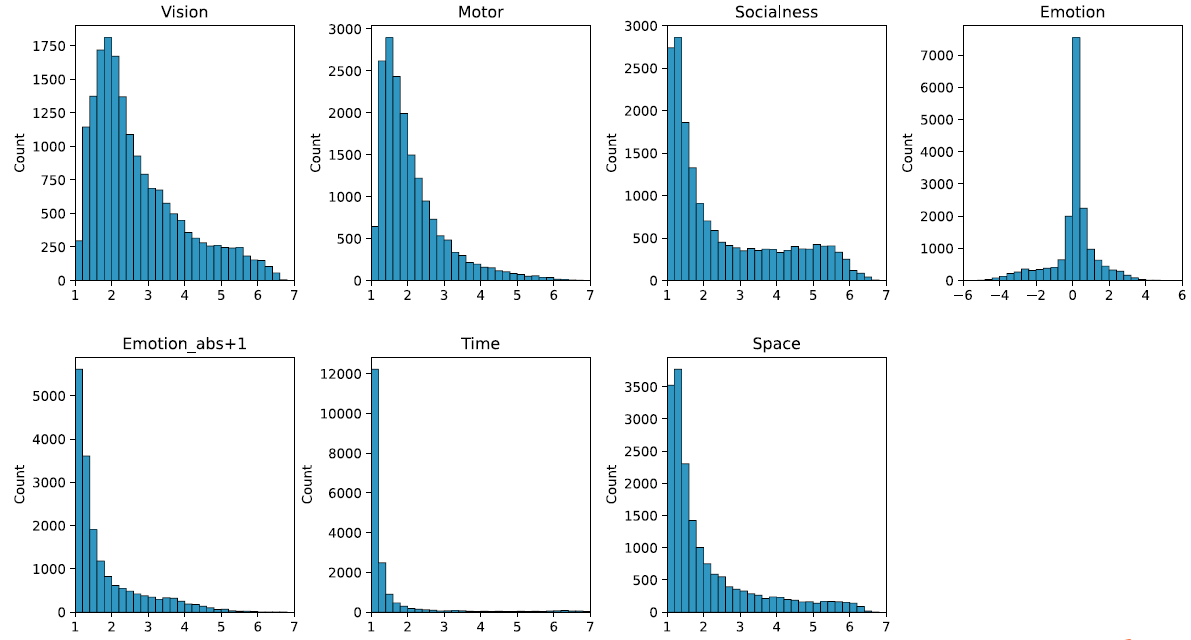
圖1:17940個中文詞在各個語義維度的主觀評分結果分布
橫軸表示結果的分數段,縱軸表示該分數段上的詞匯數量。其中情感維度的原始評分范圍是-6到6,分別代表極端消極和積極的情感,為了衡量詞匯絕對情感性的高低,研究者額外提供了這一評分的絕對值加1的分數作為另一個情感語義維度測量
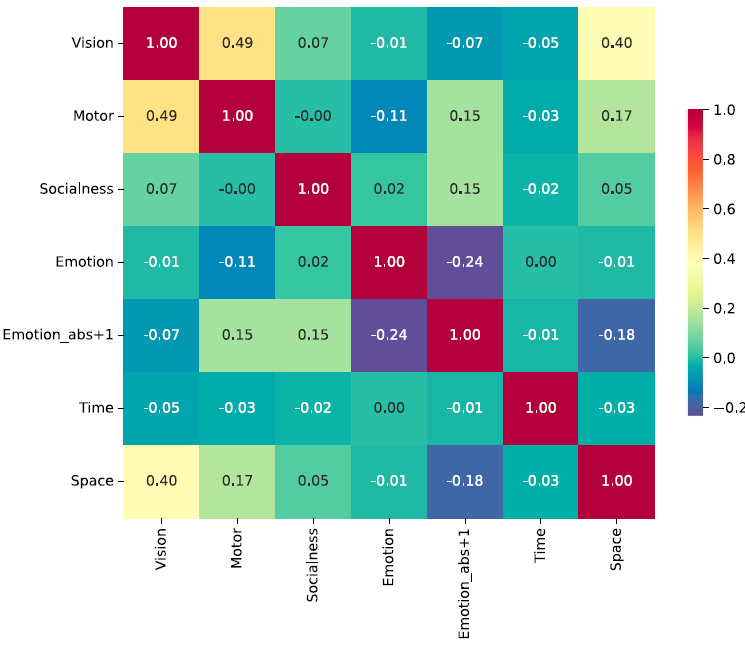
圖2:17940個中文詞在各個語義維度的評分結果見的相關系數
六維語義數據庫的發布將助力相關領域研究者對自然語言的語義信息進行高效、大規模、可解釋地量化分析,有力地推動心理學、腦科學、人工智能等相關領域的研究。
該數據庫已共享在OSF repository(https://doi.org/10.17605/OSF.IO/N5VKE),并通過心理科學數據銀行發布(https://cstr.cn/31253.11.sciencedb.psych.00107)。
該研究受國家自然科學基金(62036001, 31871105, 31871108)和中國科學院心理研究所自主部署項目(E2CX3625CX)資助,發表在Nature旗下數據類期刊Scientific Data。論文第一作者為中科院自動化所王少楠副研究員,通訊作者為中科院心理所林楠副研究員。
論文信息:
Wang, S., Zhang, Y., Shi, W., Zhang, G., Zhang, J., Lin, N.*, & Zong, C. (2023) A large dataset of semantic ratings and its computational extension. Scientific Data, 10, 106. https://doi.org/10.1038/s41597-023-01995-6
附件下載: