
心理所構建漢語語言產生數據庫
近日,中國科學院心理研究所馮臣助理研究員、屈青青研究員及合作者在Nature旗下的Scientific Data發表漢語語言產生數據庫——A dataset of behavioral measures on Chinese word production in picture naming。
說話,看似毫不費力,但其實是人類最復雜的認知活動之一。過去幾十年,研究者們試圖澄清言語表達(又稱為“語言產生”)背后的認知架構和動態加工過程。世界上大約有7000種語言,不同語言的詞匯、語音、字形系統大相徑庭。現有的實證研究與理論框架主要基于印歐語系。與印歐語言不同,漢語有獨特之處:漢語屬于漢藏語系,是一種聲調語言,同一個音節的不同音調表示不同的詞匯與意義,大多數印歐語言則不使用聲調來區分詞義。其次,印歐語言采用字母拼寫系統,而漢語采用非字母書寫系統。另外,漢語的語音與字形的對應關系較為復雜,例如,聲音/shu/可以對應“書”、“梳”、“樹”或“薯”等多個不同的字形)。漢語研究對回答跨語言普遍性和特異性具有獨特價值和貢獻。的確,一些研究已經表明,音位是印歐語言語音編碼的主要加工單元,而音節是漢語語音編碼的主要加工單元(O’Seaghdha et al., 2010)。
然而,目前大部分關于語言產生的研究側重于印歐語言,而對于漢語這一非印歐語言的研究則相對有限。此外,這些研究主要關注于口語產生過程,對于書寫等字形產生的關注則明顯不足。同時,許多研究依賴于較小的樣本量和有限的實驗刺激,這可能導致統計效力不足和研究結果的可重復性問題。構建漢語語言產生數據庫的需求與日俱增。
此次發表的漢語語言產生數據庫記錄了667名被試在7種不同語言產生任務中的約20萬個試次的反應時間,以及實驗材料的多個語言學變量(如:詞頻、字頻、音節頻率、習得年齡等)。該數據庫為研究漢語口語和書寫產生的語言加工提供了豐富數據資源,為探索漢語產生的普遍性與特異性提供了數據基礎。此外,該數據庫對于開發漢語語言產生的人工智能模型具有獨特價值與貢獻,有望推動語言認知科學與人工智能領域的交叉與共同進步。
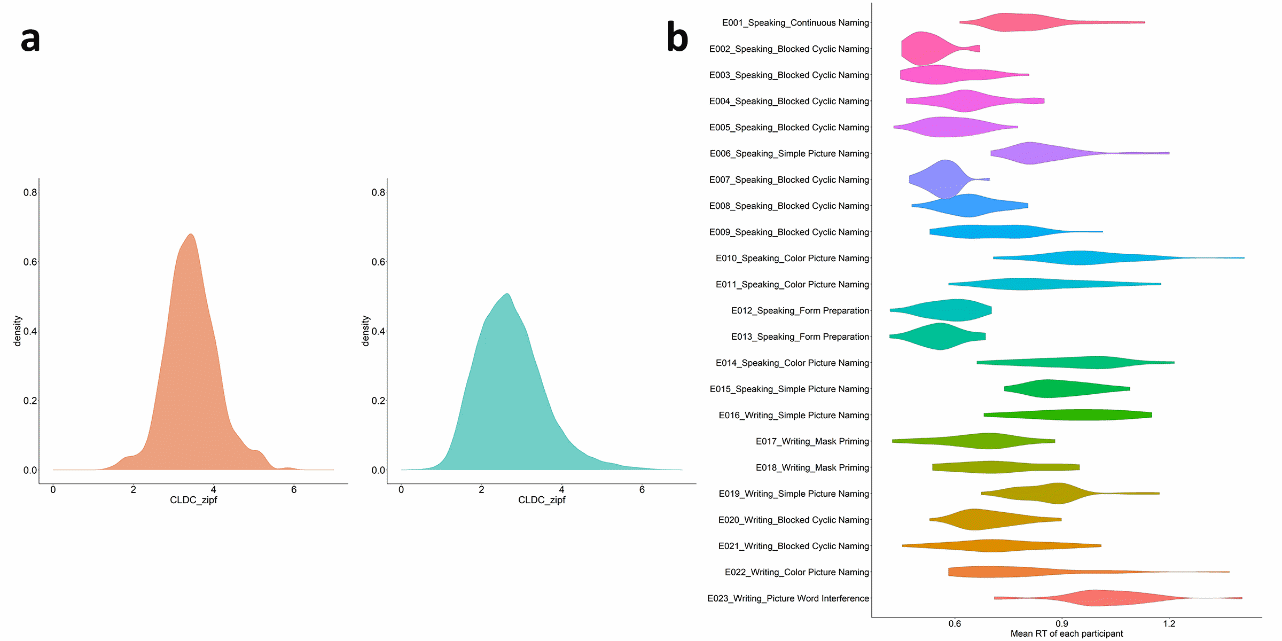
圖1.(a) 數據庫所包含詞匯的詞頻分布;(b)不同實驗任務下的反應時分布特征(右,單位:秒)
注:圖a中,左側為該數據庫中包含詞匯的詞頻分布,右側為CLDC詞匯庫(Chinese Linguistic Data Consortium,現代漢語通用詞表)中的詞頻分布。在數據庫中,詞頻的分布與大型詞匯庫相似,顯示出廣泛的分布范圍。圖b展示了不同實驗任務和范式的反應時間(以秒為單位),平均反應時間介于450毫秒至1500毫秒之間。使用相同實驗范式的實驗呈現出相似的反應時間分布,而不同范式的實驗反應時間分布則顯示出較大的差異。實驗材料較少的實驗,如cyclic blocking paradigm,其反應時間更快且分布更集中;而實驗材料較多的實驗,如simple picture naming,其反應時間較慢且分布更廣。
該數據庫發表在Scientific Data。第一作者為心理所馮臣助理研究員,通訊作者為屈青青研究員。該數據庫已共享在OSF repository(https://doi.org/10.17605/OSF.IO/6GTZH),并通過心理科學數據銀行發布。
該研究得到了國家自然科學基金(No. 32171058, No. 31771212 and No. 62061136001),北京市科技新星項目、中國科協青年人才托舉項目(YESS20200138)、中國科學院青年創新促進會項目,中國科學院心理研究所“揭榜掛帥”項目以及中國科學院行為科學重點實驗室的支持(Y5CX052003)。
論文信息:
Feng, C., Damian, M.F. & Qu, Q.* (2024). A dataset of behavioral measures on Chinese word production in picture naming.?Scientific Data,?11, 185. https://doi.org/10.1038/s41597-024-03022-8
附件下載: