
心理所基于經遺傳算法優化的誤差反向傳遞神經網絡提出漢語發展性閱讀障礙兒童的鑒別模型
發展性閱讀障礙(developmental dyslexia,DD)是一種在獲得閱讀技能方面的特殊困難,影響著5% -17%的學齡兒童,且不能單純地歸因于智力水平、視敏度問題以及學校教育的欠缺。閱讀障礙是兒童學習障礙的主要類型,超過70%的學習障礙兒童存在閱讀困難。由于致病機理不清,缺乏標準的測試工具,發展性閱讀障礙的識別和診斷一直是該領域一個巨大的挑戰。
誤差反向傳遞神經網絡(back-propagation neural network, BPNN)是人工神經網絡(artificial neural network, ANN)的一種類型,具有非線性、自主學習、容錯性良好、自我組織以及自適應性等優點,可以通過提供準確的預測來輔助醫學診斷。以往研究表明,BPNN模型在醫學預測方面優于Logistic回歸模型。已有一些研究使用BPNN模型來鑒別閱讀障礙或其他學習障礙,表現出良好的預測精度,顯示BPNN模型可作為識別閱讀障礙兒童的有效工具。然而,這些模型僅應用于拼音文字系統閱讀障礙的鑒別。由于漢語和拼音文字在認知加工上存在很大的差異,影響閱讀障礙的潛在認知因素也不完全相同,并且不同語言的閱讀相關認知技能對閱讀障礙的鑒別貢獻也有很大的不同,拼音文字閱讀障礙的鑒別模型并不能直接應用于漢語閱讀障礙的鑒別。
近日,中國科學院行為科學重點實驗室畢鴻燕研究組構建了一個經遺傳算法優化的BPNN (GA-BPNN)模型,基于近十年來建立的漢語閱讀障礙兒童認知行為數據庫(人口學數據、閱讀相關認知技能成績)對模型進行訓練和驗證,開發了針對漢語發展性閱讀障礙兒童的鑒別模型。
結果表明,GA-BPNN模型的總體鑒別準確率為94%,并且各項鑒別指標均優于以往的Logistic回歸模型。進一步分析還發現,閱讀準確性對鑒別漢語發展性閱讀障礙的貢獻最大,語音意識、拒絕假字正確率、語素意識、閱讀流暢性、數字快速命名和拒絕非字反應時對鑒別漢語發展性閱讀障礙也具有重要的貢獻。其中,語素意識的鑒別貢獻排名隨年級的增加而上升,但數字快速命名的鑒別貢獻排名隨年級增加而下降。
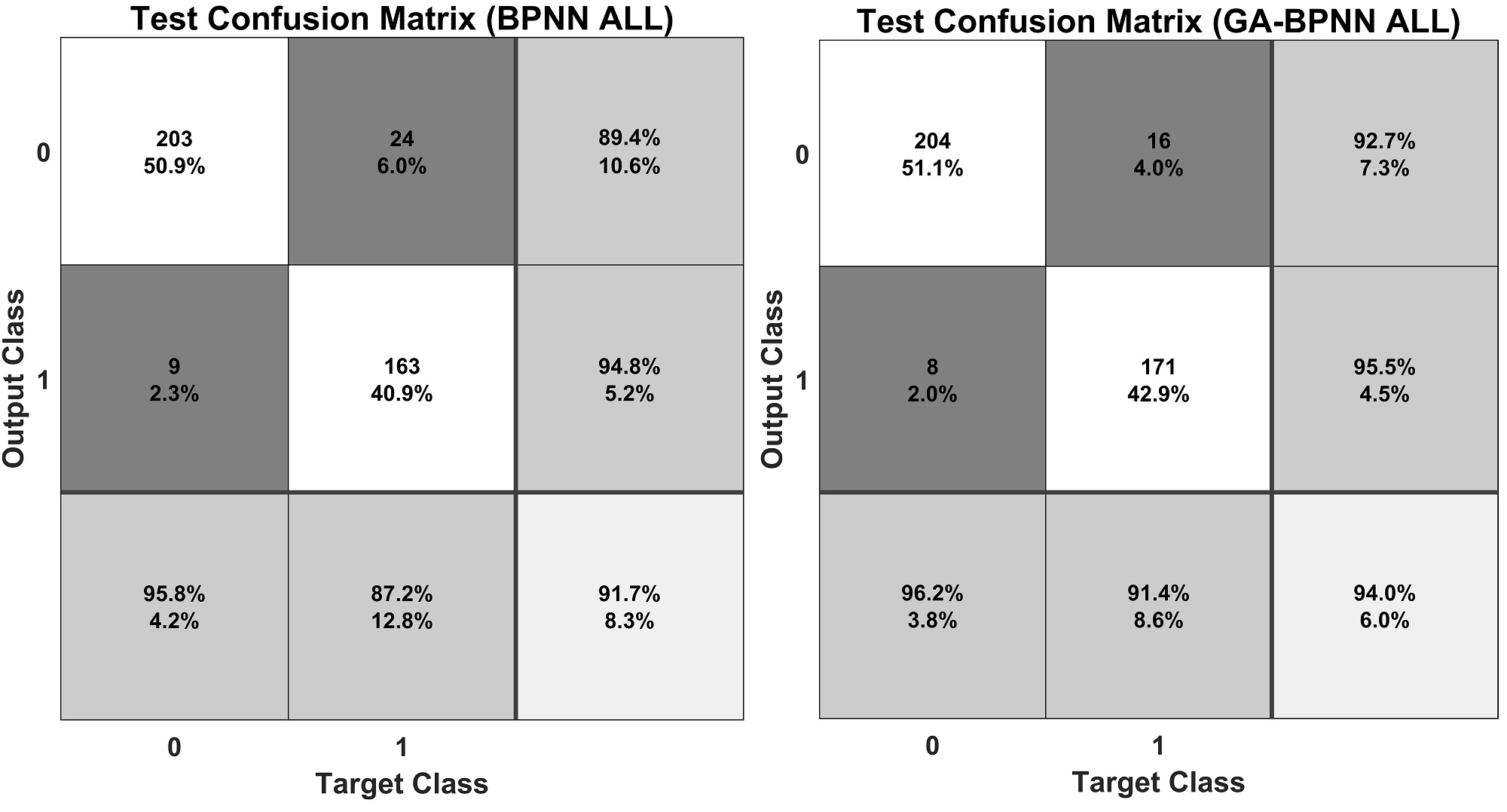
圖1 神經網絡模型對全體數據鑒別結果的混淆矩陣
注:左圖為basic BPNN模型的混淆矩陣,右圖為GA-BPNN模型的混淆矩陣
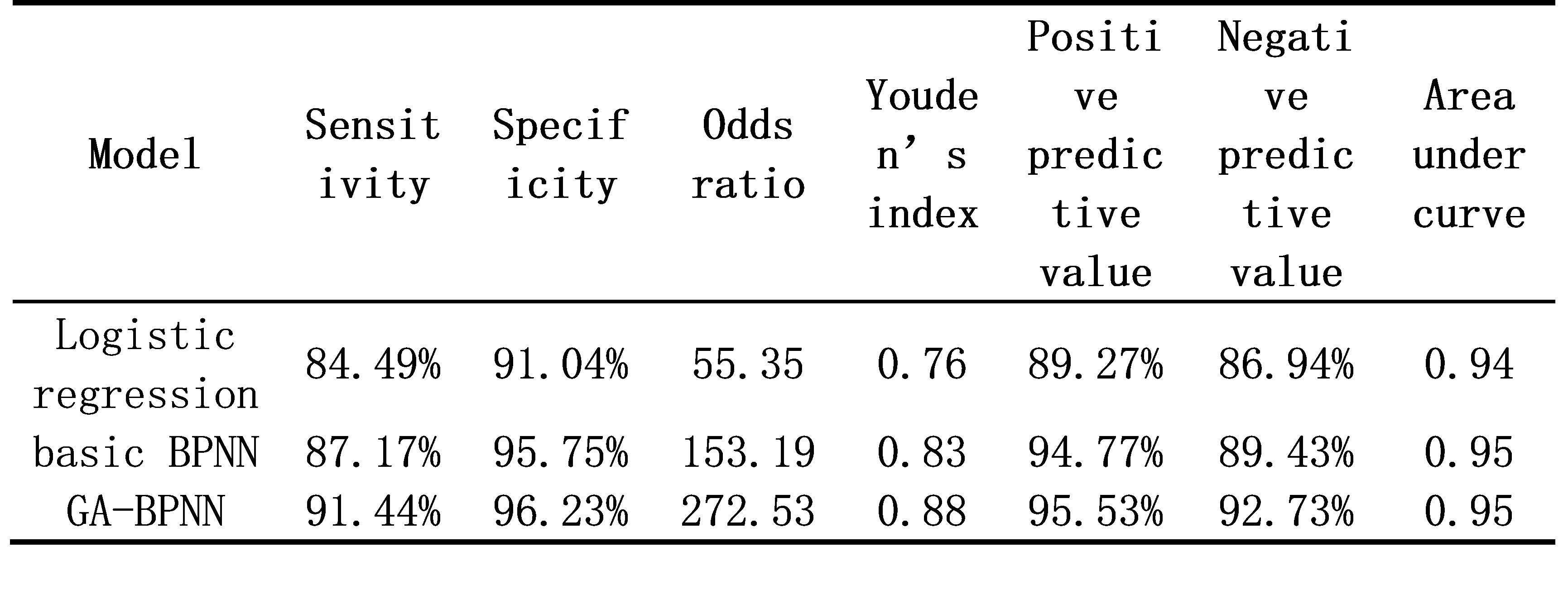
表1 三個模型對全體數據的鑒別評估指標
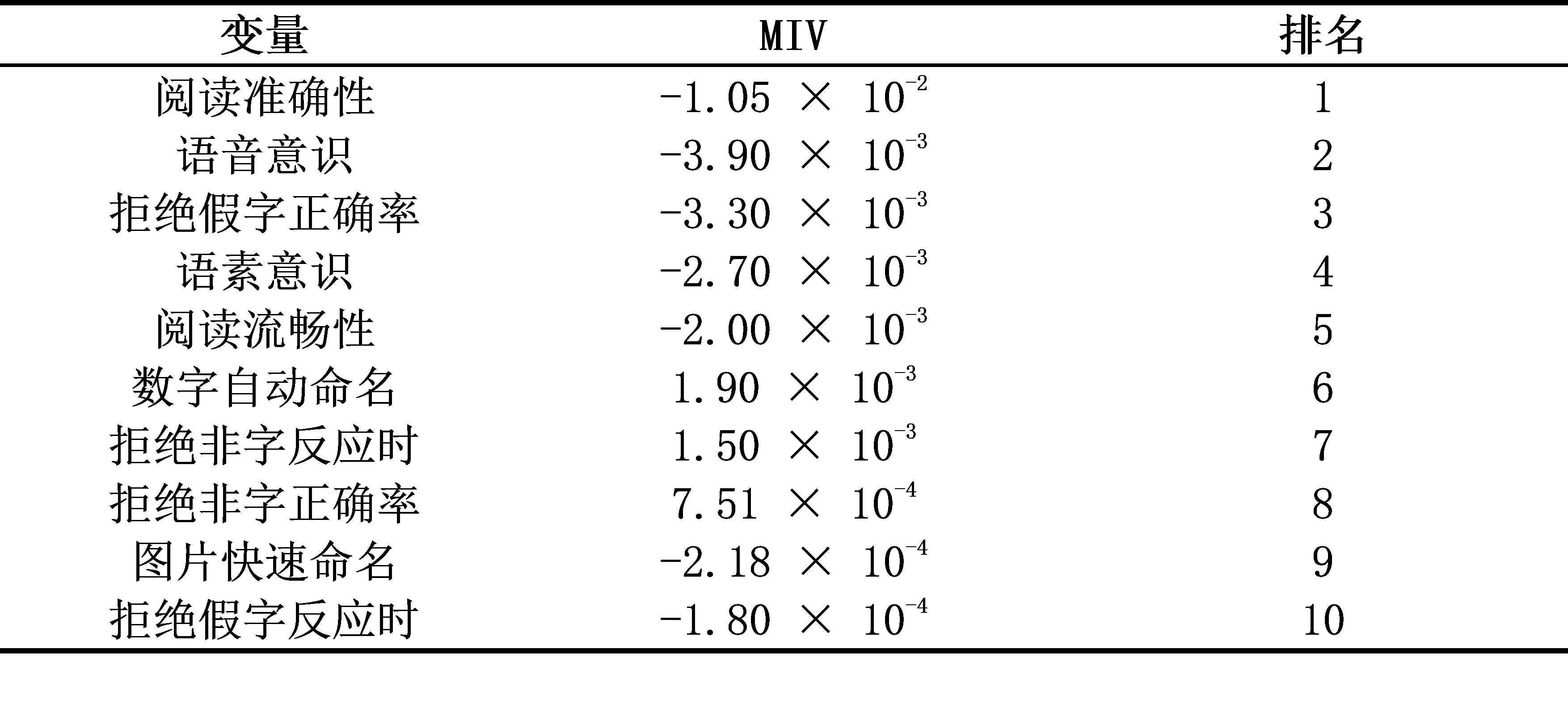
表2 閱讀相關認知技能的平均影響值(MIV)及排名

表3 兩個年級組閱讀相關認知技能的MIV及排名
該研究使用經優化的ANN模型鑒別發展性閱讀障礙兒童,構建的GA-BPNN模型對有/無發展性閱讀障礙的中國兒童具有良好的鑒別能力。未來該模型的應用可以為漢語發展性閱讀障礙提供更有針對性的預防和治療策略,也為漢語發展性閱讀障礙的人工智能專家診斷系統奠定基礎。
該研究受到國家自然科學基金項目(31671155)的資助,數據來源于畢鴻燕研究組行為與腦成像數據庫,并得到心理所圖書館的數據存儲及管理的支持。相關文章已在線發表于計算機科學/人工智能領域學術期刊Expert Systems With Applications。
論文信息:Wang, R. Z., & Bi, H. Y. (2022). A predictive model for Chinese children with developmental dyslexia—Based on a genetic algorithm optimized back-propagation neural network. Expert Systems with Applications, 187, 115949.
https://doi.org/10.1016/j.eswa.2021.115949.
附件下載: