
心理所建立中文文字概率詞匯表與時間間隔表述開放數據庫
在做決定時,人們幾乎每天都在面對概率和時間信息:事情發生的可能性有多大?結果會在多久之后出現?這些信息關乎人們的風險評估、未來規劃以及對復雜事件進程的理解,是個體做出明智決策的重要基礎。在現實中,概率和時間信息往往并非以精確的數字呈現,而是更多以“可能”“大概”“等一會”等模糊的文字形式出現。人們如何理解這些模糊的概率與時間表述?
為回答這一問題,中國科學院心理研究所饒儷琳研究組開展了兩項研究,分別建立了中文文字概率詞匯表和中文時間間隔表述開放數據庫。
研究一系統收錄了343個常用中文文字概率詞匯(如“可能”“不太可能”),并為每個文字概率提供了對應的數字概率、隸屬函數和詞頻數據,建立了中文文字概率詞匯表。
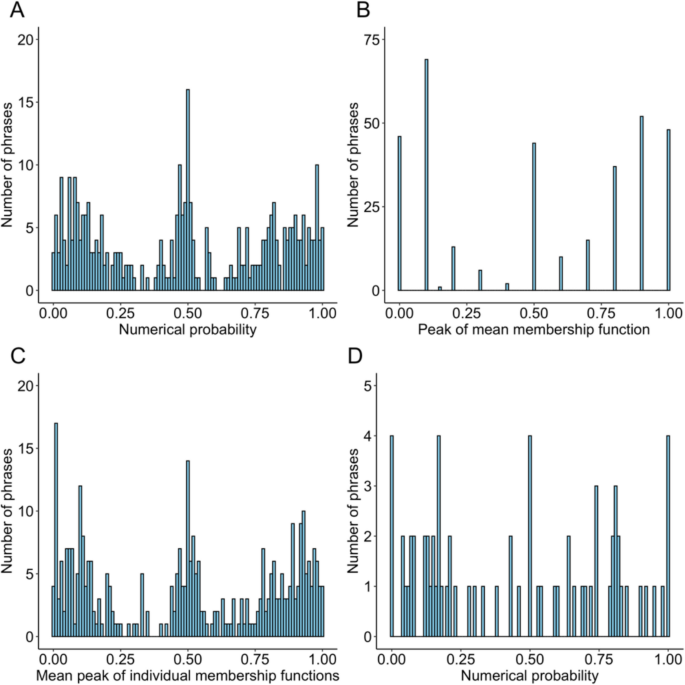
圖1. 中文文字概率詞語分布
研究團隊進一步結合實驗測量、大規模語料分析與計算建模,揭示了中文文字概率的數值分布特征,并與英文文字概率進行了跨語言對比,發現中文使用者對小概率事件賦予的主觀價值較低(見圖2)。
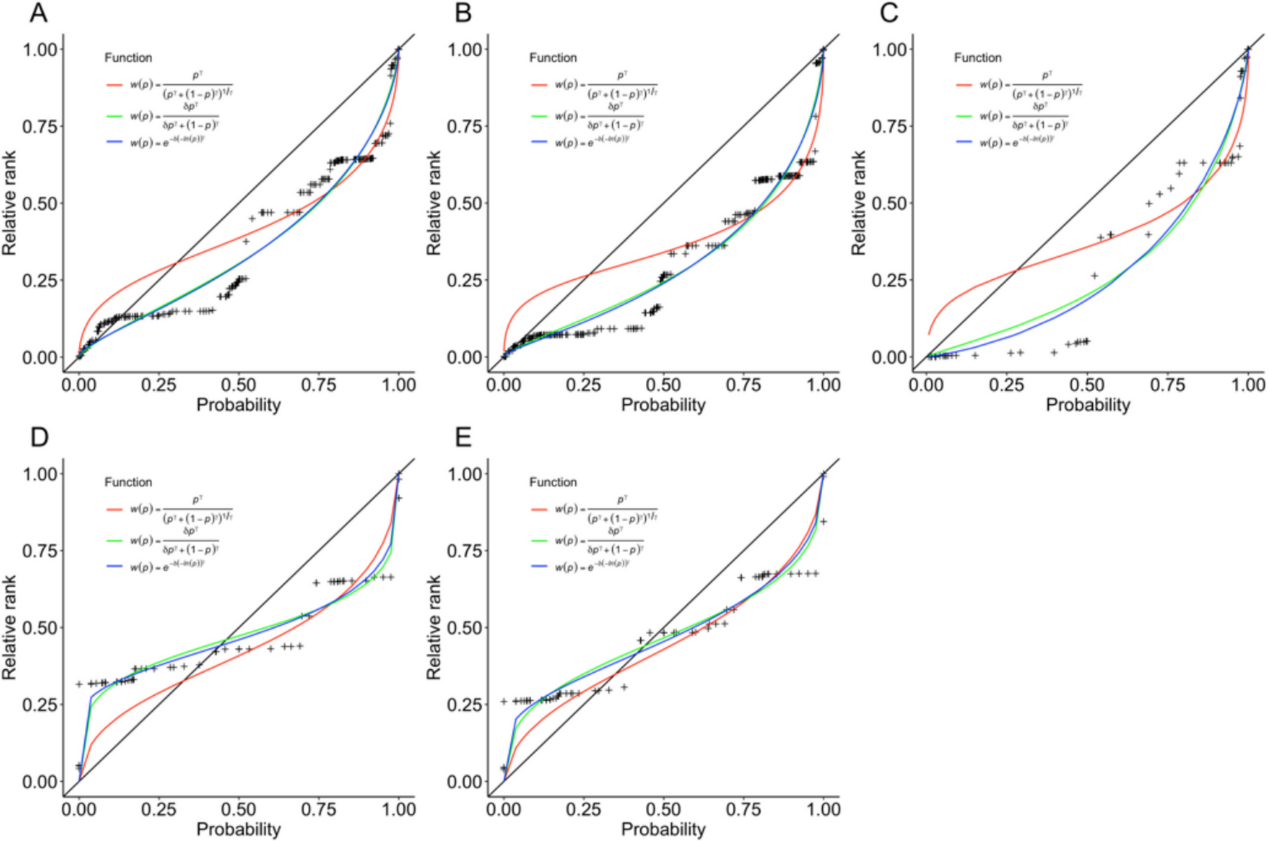
圖2. 中英文文字概率主觀價值分布與比較
研究進一步提出了七個高頻文字概率的標準化基準,可廣泛應用于機構風險溝通、概率語言標準化及心理語言學研究。該成果為風險溝通、跨文化概率語言研究、決策科學與文本分析提供了重要工具。
研究二構建了首個中文時間間隔表述開放數據庫,涵蓋2101個時間間隔表述,包括數字時間間隔詞語(如“3天”“兩小時”)與文字時間間隔詞語(如“很快”“一陣子”)。每個時間間隔表述均配有相應的數字時間長度和詞頻信息(見圖3)。
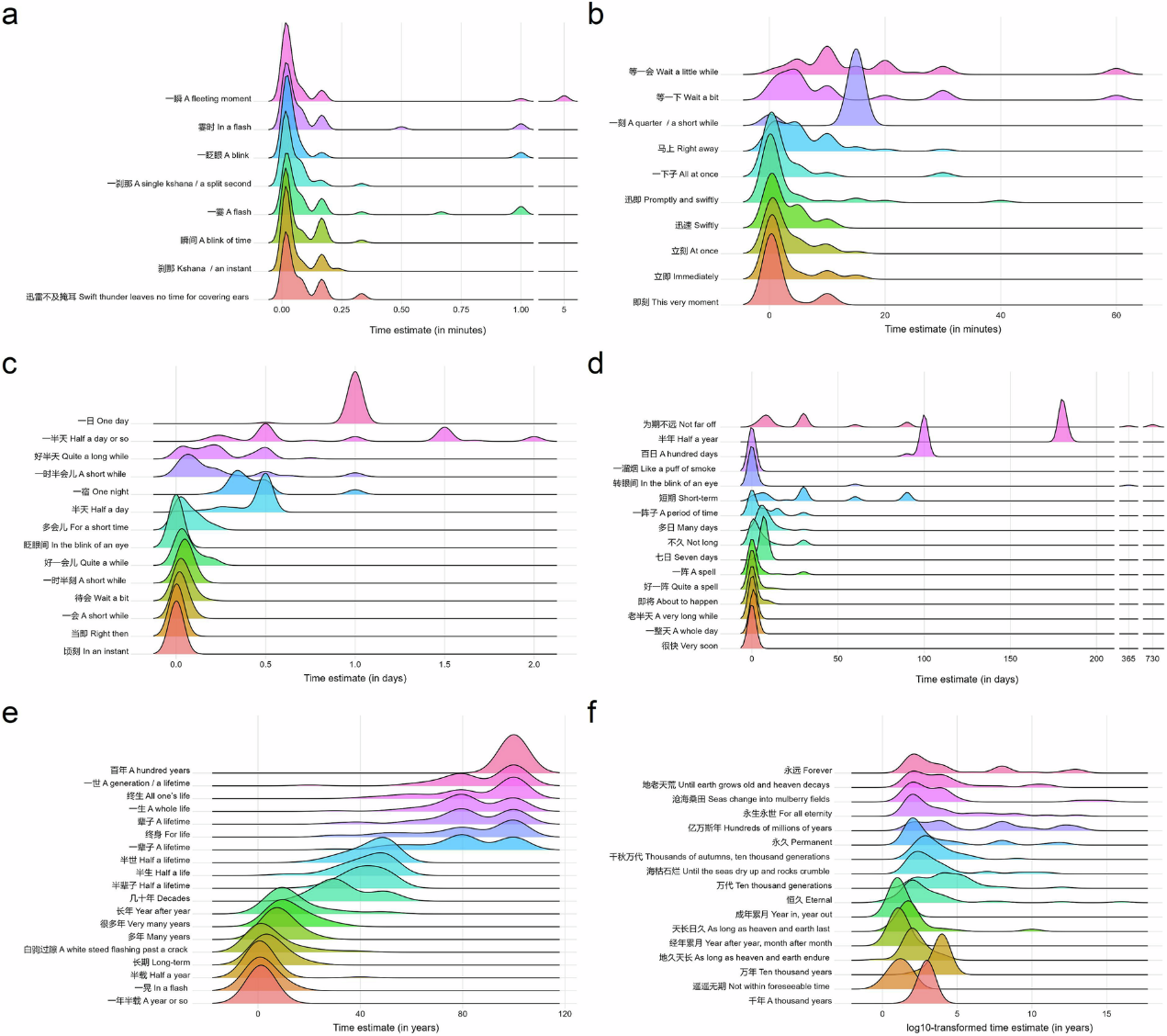
圖3. 文字時間間隔表述及其數字表征
該研究首次建立了模糊的時間間隔表述與客觀時間長度的對應關系。分析結果顯示,該數據庫可以準確再現人類時間折扣行為的特征模式,驗證了該數據庫的質量和有效性(見圖4)。該數據庫為心理學、語言學和計算科學等領域的研究人員提供了有效的研究工具,為時間信息加工、行為決策建模和自然語言處理等提供了數據基礎。
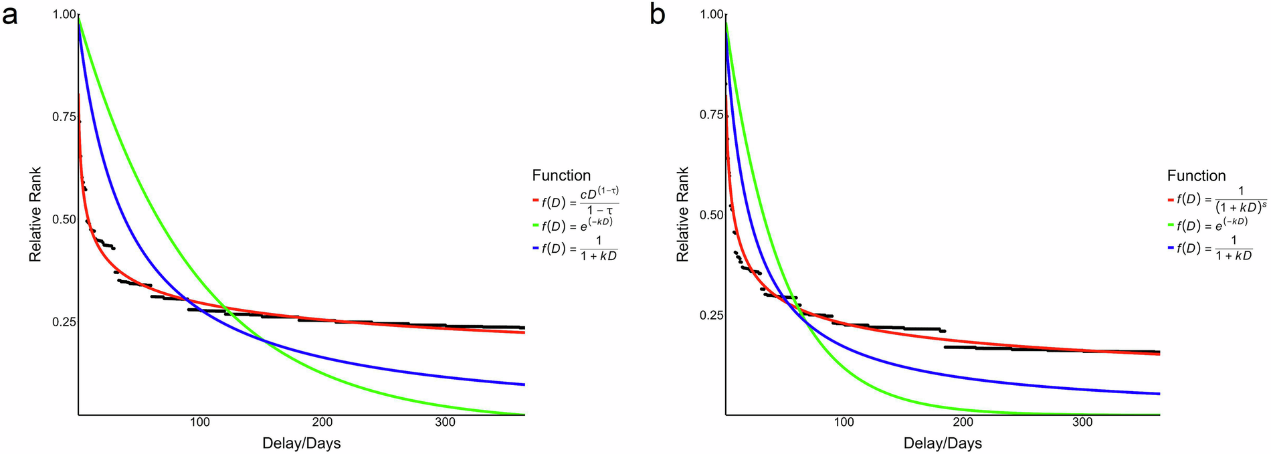
圖4. 采用該數據庫擬合個體延遲時間的主觀價值分布
研究一的成果已發表于Behavior Research Methods,數據庫鏈接https://doi.org/10.57760/sciencedb.19815?。心理所博士研究生隋曉陽(已畢業)為論文第一作者,饒儷琳研究員為通訊作者。該研究受到國家自然科學基金(72371237、92046006、72501312)和北京市社會科學基金青年學術帶頭人項目(24DTR065)的資助。
研究二的成果已發表于Scientific Data,數據庫鏈接https://doi.org/10.57760/sciencedb.28888 。心理所博士研究生張思琦和碩士研究生牛佳雯(已畢業)為論文共同第一作者,隋曉陽和饒儷琳為共同通訊作者。該研究受到國家自然科學基金(72371237、92046006)和北京市社會科學基金青年學術帶頭人項目(24DTR065)的資助。
兩項數據庫已面向全球研究者公開共享,有望在中文語料資源建設、人工智能文本理解及跨文化心理學研究等領域提供參考與啟發。
論文信息:
Sui, X.-Y., Niu, J.-W., Liu, X., Rao, L.-L.*(2025). Bridging numerical and verbal probabilities: Construction and application of the Chinese Lexicon of Verbal Probability. Behavior Research Methods, 57, 335. https://doi.org/10.3758/s13428-025-02853-6
Zhang, S.-Q.#, Niu, J.-W.#, Liu, X., Sui, X.-Y.*, Rao, L.-L.*(2025). An open dataset of Chinese duration expressions. Scientific Data, 12, 1732. https://doi.org/10.1038/s41597-025-06016-2
附件下載: