
心理所發布首個基于大規模自發言語的漢語學前兒童詞匯數據庫
詞匯數據庫是心理語言學和認知神經科學研究的重要基礎工具。然而,現有多數漢語詞匯數據庫主要來源于成人文本、兒童讀物或動畫等輸入性材料,難以真實反映學前兒童在自然交流中“能說什么”以及“如何說”。學前階段是詞匯快速增長的關鍵時期,但兒童的表達性詞匯與理解性詞匯在規模和分布上存在顯著差異。因此,構建基于兒童真實口語產出的專門數據庫,對于深入探究兒童語言發展與認知機制具有重要價值。
近日,中國科學院心理研究所李甦研究組發布了漢語學前兒童口語詞匯數據庫(Chinese Preschool Children’s Spoken Lexical Database,CPCSLD)。該數據庫基于648名北京地區3–6歲兒童在同伴對話情境中的自發言語構建,語料涵蓋旅行、玩具、圖書、動畫、機器人和游樂園等貼近兒童日常生活的主題。整個語料庫共包含約120萬詞次、21372個不同詞條、1147個帶聲調音節和400個不帶聲調音節,并分別構建了幼兒園小班(K1)、中班(K2)和大班(K3)三個年齡段的子數據庫。
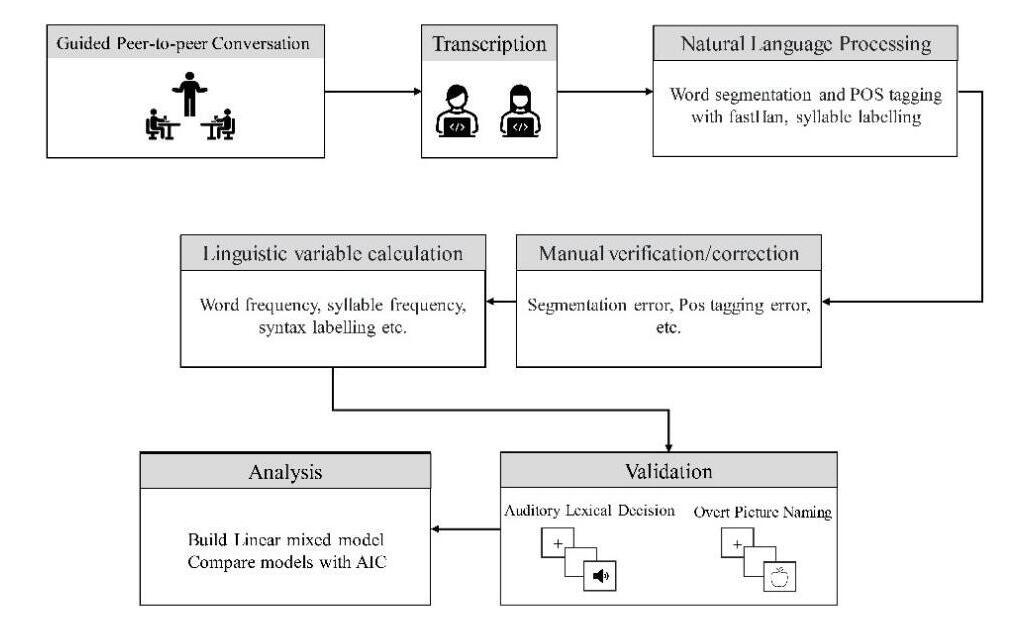
圖1. 詞匯數據庫的構建流程
該數據庫系統性地提供了詞匯層面和音節層面的多維信息,涵蓋詞頻、詞長、詞類、音節頻率(帶聲調/不帶聲調)等多種指標,可用于精細刻畫學前兒童口語詞匯的結構特征和發展變化。分析結果顯示,隨著年齡增長,兒童自發言語中多音節詞比例逐漸增加,詞匯結構日趨復雜;不同詞類在表達性語言中的分布也呈現出鮮明的發展特征。
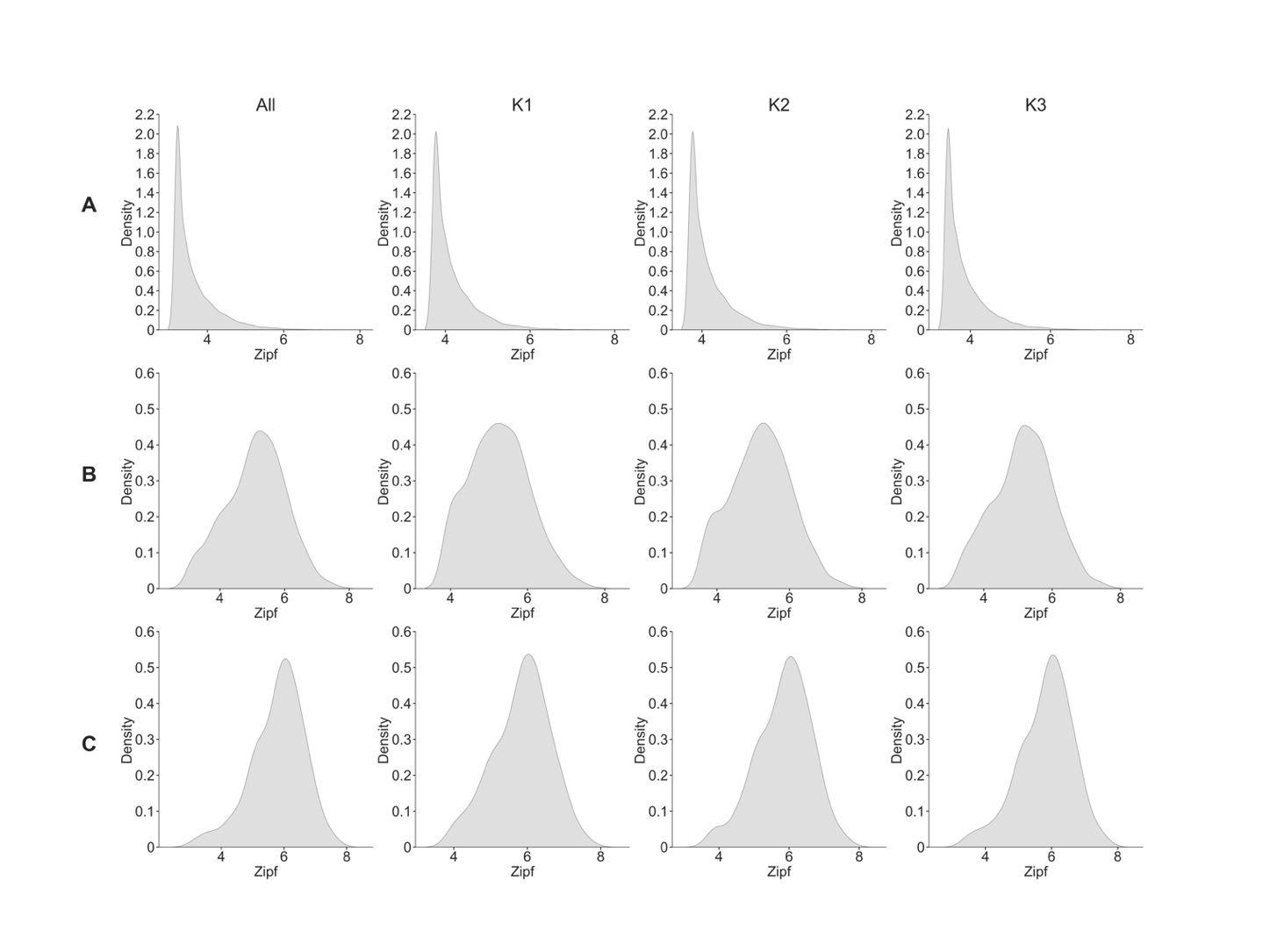
圖2. 詞頻和音節頻率的分布
A) 總詞匯庫的詞頻分布和各年齡組詞頻分布;B)帶聲調音節的總詞匯庫頻率分布和各齡組分布;C)不帶聲調音節的總詞匯庫頻率分布和各年齡組分布
為檢驗數據庫的心理語言學效度,研究團隊進一步將 CPCSLD 與多個已有漢語詞匯數據庫進行比較,并用于預測學前兒童在語義判斷任務和圖片命名任務中的表現。結果表明,CPCSLD 在預測圖片命名反應時和正確率方面表現出顯著優勢,優于基于成人語料或輸入性兒童語料構建的數據庫;而在以詞匯理解為主的語義判斷任務中,其優勢則相對有限。這一結果表明:基于兒童自發言語構建的詞匯數據庫,更能捕捉學前兒童言語產生過程中的關鍵統計特征。
該數據庫是首個專門面向漢語學前兒童表達性詞匯、以自然口語產出為基礎的漢語詞匯數據庫,為兒童語言發展與言語產生研究提供了新的工具。CPCSLD 不僅可用于研究學前兒童詞匯和言語產生的發展機制,也可服務于兒童語言評估、語言障礙早期篩查以及教育干預研究。同時,該數據庫為探索兒童心理詞匯表的組織結構、發展軌跡,及其神經基礎提供了重要的數據支撐。
目前,CPCSLD 數據庫及相關分析代碼已在國家科學數據中心平臺公開共享(https://www.scidb.cn/en/s/Vb6vIb),供國內外研究者免費使用。研究團隊希望該數據庫能夠推動學前兒童語言發展研究的深入開展,并為兒童語言教育與干預實踐提供科學依據。
該研究得到了國家自然科學基金(31571140)和中國科學院心理所自主部署項目(Y5CX052003)的支持。
研究論文已在線發表于Behavior Research Methods。心理所助理研究員馮臣為論文第一作者,李甦研究員為論文通訊作者。心理所研究助理王嵩為論文共同作者。
論文信息:Feng, C., Wang, S., & Li, S. (2026). CPCSLD: A lexical database of Chinese preschool children’s spoken words.?Behavior Research Methods,?58(2), 54. DOI: https://doi.org/10.3758/s13428-025-02931-9
附件下載: